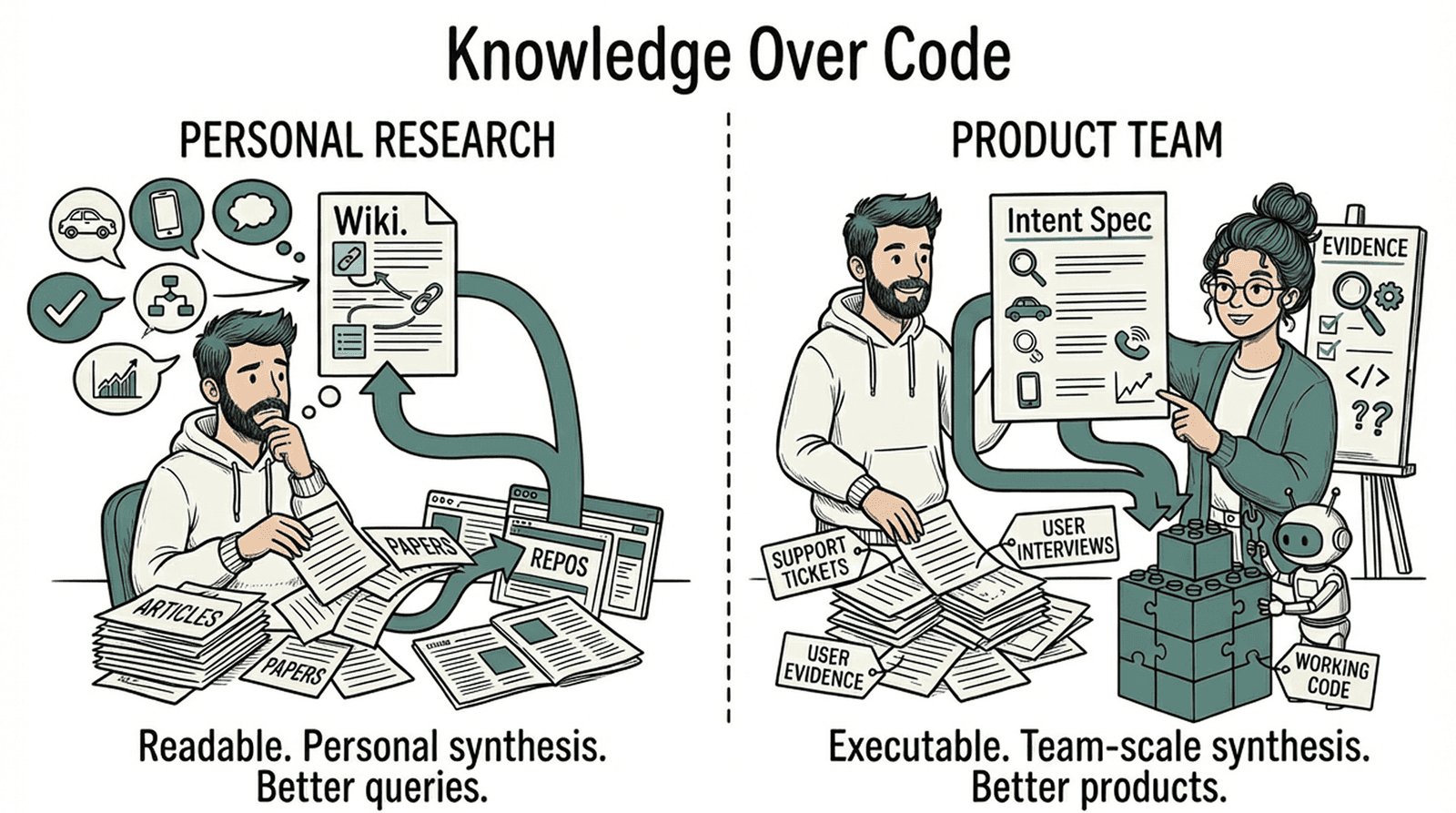
There's a pattern emerging in how the best teams use AI, and it has nothing to do with writing code faster. It's about compiling messy reality — user evidence, research, conflicting signals — into structured knowledge that machines can act on. Not documentation. Not wikis. Executable intent.
Andrej Karpathy just described one half of this pattern. In a recent post, he noted that a large fraction of his token throughput now goes less into manipulating code and more into manipulating knowledge — using LLMs to build personal knowledge bases from raw research materials. The core idea: index source documents, let the LLM compile them into structured, interlinked knowledge, query it. The outputs feed back in. It compounds.
He called it a significant product opportunity. We agree — but the opportunity is bigger than a personal knowledge base. Karpathy's compiled wiki is readable: optimized for a human to query and understand. Product teams need something different. They need knowledge that instructs — structured intent that AI agents can execute directly. That's the second half of the pattern, and it's the part that changes how software gets built.
The Compilation Pattern
What Karpathy described isn't a personal productivity hack. It's a pattern that's emerging everywhere AI replaces execution speed as the bottleneck.
The pattern is: raw inputs → structured knowledge → executable output.
For Karpathy's research, that's articles → wiki → insights. For software teams, it's something more specific: user evidence → intent specs → working code.
Think about what actually slows down a team that has access to Cursor, Claude, and Copilot. It's not writing code. A competent developer with today's tools can ship a feature in hours that used to take days. The bottleneck has moved upstream.
What slows teams down is figuring out what to build and why. It's the PM synthesizing twelve customer interviews, three support ticket trends, and a competitive shift into a coherent feature spec. It's the tech lead translating "users are churning at checkout" into testable outcomes and edge cases that an AI agent can actually execute against.
That synthesis — turning scattered signal into structured intent — is where all the leverage is. And it's still mostly manual.
Raw Evidence Is Everywhere. Structure Is Nowhere.
Every product team is drowning in raw signal. Support tickets. User interviews. Session recordings. NPS comments. Sales call transcripts. Competitor launches. Internal Slack debates about what to prioritize.
This is Karpathy's raw/ directory. Unstructured, scattered, full of signal if you could just extract it.
The problem is that this raw evidence never gets structured into anything an AI agent can act on. It lives in Notion docs, Slack threads, and people's heads. When it's time to build, someone writes a Jira ticket from memory, a developer prompts an AI agent with half the context, and the agent builds something that works for the happy path and misses everything else.
The gap isn't between the ticket and the code. It's between reality and the ticket. Between raw evidence and structured intent.
From Knowledge Base to Executable Spec
So what does it actually mean for compiled knowledge to instruct rather than inform?
An intent spec isn't documentation. It's a contract between a human decision-maker and an AI executor. It needs:
- An objective tied to a real user problem, anchored in specific evidence
- Outcomes that are testable — not "improve the experience" but "users complete checkout without needing to contact support"
- Edge cases derived from actual user behavior, not imagined from a conference room
- Constraints that reflect business reality — performance budgets, compliance requirements, migration paths
Here's what that looks like concretely. Three support tickets about failed payments, a user interview quote — "I thought my order went through but nothing happened" — and a cart abandonment metric spiking 40% after a recent deploy. In Karpathy's model, these become wiki articles you can query. In an intent spec, they become load-bearing structure: the metric anchors the objective, the failure modes from the tickets become specific edge cases, and the user's own words define the success criterion.
When raw evidence crystallizes into this structure, something powerful happens. The spec becomes a direct input to AI coding agents. The synthesis step doesn't just inform — it instructs.
The Compounding Effect
Karpathy noted that his queries and explorations "always add up" in the knowledge base. Every question he asks makes the wiki richer. This is the most underrated property of the pattern.
Product teams that structure evidence into specs get the same compounding effect. Each piece of evidence strengthens not just the current spec, but the entire product context. When you go to write the next spec, the evidence is already there — categorized, linked, anchored to past decisions.
A support ticket about checkout friction doesn't disappear into a Slack thread. It gets structured — linked to three prior checkout observations from last month, the cart abandonment metric that spiked after a recent deploy, and the user interview quote about confusing error messages. The next time any spec touches checkout, that accumulated intelligence surfaces automatically. No one has to remember it was there.
This is the difference between a team that starts every feature from a blank Jira ticket and a team that builds on compounding product knowledge.
Why This Matters Now
Six months ago, the AI discourse was about coding speed. Cursor is amazing. Claude can write entire features. Ship faster.
That discourse is maturing. People are discovering what happens after the first weekend of vibe coding — the hangover when a second developer joins and can't understand why anything was built the way it was. The quiet realization that Jira tickets fail AI agents because they were designed to trigger conversations, not instruct machines.
There's also a question of scale. Karpathy's setup works beautifully for personal research — one person's mental model, a bounded set of sources, a single editorial voice. Product teams deal with something messier: multi-stakeholder evidence accumulating over months, contradictory signals, shifting priorities, and decisions that need to survive team turnover. A personal wiki or general RAG pipeline doesn't hold up when the knowledge is contested, evolving, and needs to instruct machines — not just inform humans.
Karpathy's shift — from code manipulation to knowledge manipulation — is the same realization from a different angle. When generating code is cheap, the expensive thing is knowing what code to generate. When execution is abundant, specification is scarce.
The teams that figure out this synthesis step — raw reality → structured intent → executed code — will build products that are qualitatively different from teams that prompt their way forward and hope for the best.
The spec is becoming the product. The pipeline that produces it is becoming the competitive advantage.
Pathmode is the intent engineering platform for product teams building with AI. We turn raw product evidence into structured specs that AI agents can execute — the team-scale version of the workflow Karpathy is pioneering for research.
Don't Just Write Code. Define Intent.
Turn user friction into structured Intent Specs that drive your AI agents.
Get Started for Free